九月份就发现的问题,打了一部分草稿。自己拖拖拉拉,硬是搞到现在才写完,不过总算是写完了了却一桩拖拉事。
前几天线上遇到个挺有意思的问题,值得记录一下。
场景:从 LIST 到 HASH
门票服务需要把即将开抢的票放进 Redis。用户抢票时,从 Redis 里原子取票、加锁、成交后写回数据库。
一开始门票数据用 LIST 存,抢到就 POP,简单高效。
后来需求改了——要支持“选座”。于是改成了 HASH,以座位号作为 field:
local seatId = ARGV[1]
local tktsKey = KEYS[1]
local lockKey = KEYS[2]
local tkt = redis.call('HGET', tktsKey, seatId)
if tkt == nil then return -1 end
if redis.call('setnx', lockKey) == false then return -2 end
redis.call('HDEL', tktsKey, seatId)
return seatId这没问题。但如果是非选座票,只要随机拿一张就行,于是脚本写成了:
local tktsKey = KEYS[1]
if redis.call('HLEN', tktsKey) == 0 then return -4 end
local rsp = redis.call('HSCAN', tktsKey, '0', 'COUNT', '1')
if #rsp < 1 then return -1 end
local nextCur = rsp[1]
local elements = rsp[2]
if #elements < 2 then return -2 end
local seatId = elements[1]
if redis.call('SETNX', seatId) == false then return -3 end
redis.call('HDEL', tktsKey, seatId)
return seatId结果线上出现奇怪现象:
HLEN 明明显示有数据,但 HSCAN 返回空数组(#rsp < 1)。
日志确认逻辑没问题,问题出在 —— cursor 总是传 0。
问题根源:HSCAN 的 cursor 用法
每次 HSCAN 返回两部分:
-
下次应使用的 cursor;
-
当前扫描到的元素。
若一直传 0,其实你每次都在从头开始扫描第 0 个 bucket —— 很可能遇到空桶。
正确写法应该循环调用 HSCAN,直到真正返回元素:
local cur = '0'
local elements = {}
repeat
local rsp = redis.call('HSCAN', tktsKey, cur, 'COUNT', '1')
if #rsp < 1 then return -1 end
cur = rsp[1]
elements = rsp[2]
if #elements >= 2 then break end
if cur == '0' then return -5 end
until false这样才能保证一定拿到数据。
深挖:dictScan 与反转位递增算法
继续往里看。Redis 的 HASH(当为 hashtable 编码时)底层是哈希桶结构。
HSCAN 对应的核心实现函数是 dictScan。
它有几个关键点:
-
每次调用返回一个 bucket 中的所有 entry;
-
如果 COUNT 不足,会跨多个桶;
-
若哈希表太稀疏,会限制单次扫描步数:
maxiterations = count * 10; -
最重要:cursor 并非简单递增,而是“反转位递增”(reverse-bit increment)算法。
用伪代码看就是:
v |= ~mask;
v = rev(v);
v++;
v = rev(v);把这段代码抠出来单独运行,只观察 cursor 的变化轨迹:
int main(int argc, char **argv) {
unsigned long pow = 4;
if (argc > 1) {
pow = strtoul(argv[1], NULL, 10);
}
unsigned long table_size = 1UL << pow;
unsigned long mask = table_size - 1;
unsigned long cursor = 0;
do {
printf("0x%04x(%lu) ", cursor & mask, cursor & mask); // 同时把16进制和10进制打印出来
cursor |= ~mask;
cursor = rev(cursor);
cursor++;
cursor = rev(cursor);
} while (cursor != 0);
printf("\n");
return EXIT_SUCCESS;
}简单测试可得输出:
./a.out 4
0x0, 0x8, 0x4, 0xc, 0x2, 0xa, 0x6, 0xe, 0x1, ...顺序完全不连续!但遍历完刚好覆盖所有桶,没有遗漏。
为什么要这么复杂?
不过为什么不采取直接由低位向高位递增来确定下一个游标位,而是要采用这反转位递增算法呢?按照文档的说法,是为了哈希桶在 resize 时,也不会漏掉桶中的元素。
那我们来细看一下其运行时的几种情况。
unsigned long dictScanDefrag(...) {
// ...
if (!dictIsRehashing(d)) {
// getting the dentries of the bucket
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
} else {
// getting the dentries from the htable[0]
do {
// getting dentries from the htable[1]
/* Increment the reverse cursor not covered by the smaller mask.*/
v |= ~m1;
v = rev(v);
v++;
v = rev(v);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
// other code
}这里是根据哈希桶是否处于重新 hash 的状态来走不同分支的,先大致了解一下 rehash 的过程。rehash 时使用相同 hash 函数,只是桶大小变化导致取余结果不同(见函数 rehashEntriesInBucketAtIndex)。
那我们当 size 呈 2 倍扩展时,同一个值对这个 size 取余的结果会如何变化。为了方便,我们先列表
| size\idx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | … |
|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 0 | 2 | 1 | 3 | ||||||
| 8 | 0 | 4 | 2 | 6 | 1 | 5 | 3 | 7 | ||
| 16 | 0 | 8 | 4 | c | 2 | a | 6 | e | 1 | … |
先讨论一下扩容缩容时,数据是如何重新分布的。
因为 size 总是 2 的幂次方。那么:
-
如果是扩容,那么原桶中的数据,可能会被分流到不同的桶中。分流的桶低位与原桶一致,因扩容而多出来的位可为0(那么还在原桶中), 也可能为 1(分流到了新桶)。比如桶大小由 4 扩容为 8, 则 0x00 中的数据可能被分流到0x00/0x04, 桶大小由 4 扩容为 16,则原来在 0x03 中的数据,可能会被分流到 0x03/0x07/0x0b/0x0f 桶中。
-
如果是缩容,显然是相同低位的桶,归并到了一个桶内。比如现在缩容到桶大小为 4,原来在 0x07 和 0x03 桶中的数据就都合并到 0x03 桶中了(因为 0x07 与 0x03 的低2位都是 0b11)
把数据的重新分布画出来,更容易看出规律:
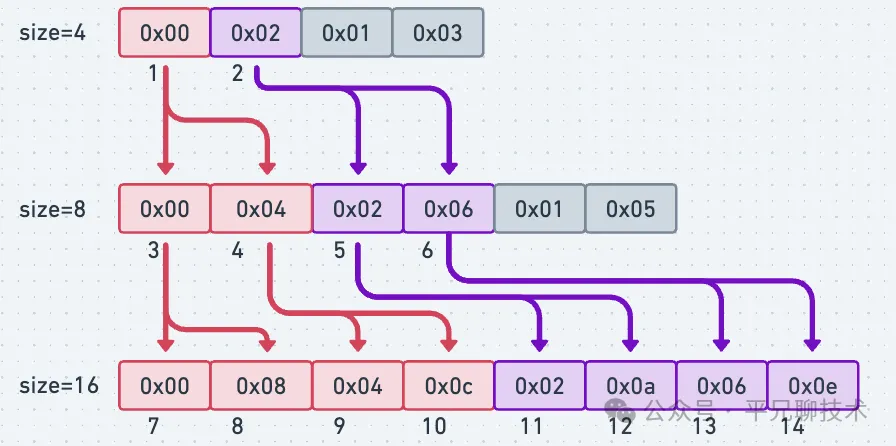
总的来说,扩容时容量每涨一个幂次,再原相邻两个桶序列间就会插入一个新的桶。
比如当在 size=8 的 hashtable 上遍历完 4 桶了,返回了 0x02 用于下一次遍历使用。下一次发起请求前扩容成 size=16 了,那么下一次我们会从 11 桶开始读数。对于已经读过的桶(3/4),他们分流的数据不会出现在 0x02前,未读的桶,他们的数据仍相对一致的在 0x02 后。我们的遍历读,不会有重复也没有 miss,完美!
关于在遍历过程中缩容的情况,读者可以自己推演一下。
我们是否有更好的选择?
但回过头来,是否有更简单直观的 cursor 计算规则?比如直接从0开始递增?
同样是先在 size=4 的情况下遍历,返回 0x02 作为下次遍历的 cursor,然后哈希表扩容到 size=8。这意味着原 0x00/0x01 桶中的数据已经被访问过了,但他们有可能会被 rehash 放到 0x04/0x05 中去(糟糕,重复访问了)。 反之,如果是正在 size=8 时遍历到了 0x06, 下次要访问 0x07 时,因为缩容 0x07 的数据被 rehash 到 0x03 了,那么用简单递增的算法,我们就访问不到这部分数据了。
可以看出,我们的访问顺序在 mod 由 2 的幂次变化过程中,保持相对原取余结果稳定,才能让我们避免重复访问/漏访问。
你可以把它理解为:cursor 的高位在变化,而低位模式保持稳定。
小结
这个线上问题的根因,其实是对 HSCAN 游标的误用。
背后隐藏的,是 Redis 为了解决扩容时遍历一致性问题所采用的一种巧妙算法。
如果你只是想“随机取一张票”,那其实
HSCAN并不是最佳方案 —— 它是遍历型命令,而不是采样型。
一句话总结:
HSCAN 不是随机取值,而是分段遍历。cursor 不动,就永远盯着同一个空桶。