看见尾缀这个“一”,就知道,这是一个新坑了。不知道还会不会有后续系列。
你们一定在看代码的时候看到过一些又可以用这种写法,又可以用另一种写法的代码;或者是一些“这到底是在干啥呢”的代码,而去搜索引擎究其原因,大都含混其词,一笔带过。好比数学课上,老师的一句“显然可得”,你就得琢磨半天,感觉老师的“显然”和你理解的“显然”不是同一回事。
所以,我们就籍着这个系列(也许会如《独唱团》一般首期即是绝唱),来捋一捋这些“显然可得”的tricks。
1. 0长度数组
Linux 内核代码中,有不少这样的结构体
struct Foo
{
...
int i;
char c;
...
double d;
char buf[0];
}上面都好理解,唯一让你有很多问候的是最末尾那个长度为0 的buf。

既然长度为0,那便没有存储空间,便不能存数据,那声明他有何用?答案是,用这个可以用来表示动态长度的数组。诚然,我也可以把buf 的定位改为char* buf ,这样不就让他指向一段动态长度的内容了嘛?但是,在内存寸土寸金的内核中,这样不就多使用了一个指针长度(4个字节)了嘛!
让我们看看他是怎么做到的。其实,我这里隐藏了一个关键的结构,size。真正的结构如下:
struct Foo
{
size_t size;
...
int i;
char c;
...
double d;
char buf[0];
}
Foo* ptrFoo = malloc(sizeof(Foo) + buf_len);
ptrFoo->size= sizeof(Foo) + buf_len;注意最后两句代码,申请Foo 的空间时,我多要了buf_len个字节,这样后面多余的这buf_len 个字节就是我的动态长度了。而buf字段可以既不占空间,又可以在我需要定位这段动态数据的时候,作为首地址。而当没有 buffer 时,则可以做到没有任何 overhead。
2. C 中的链表
在上数据结构的时候,肯定有过对链表的介绍。通常,我们是这样实现单链表的。
struct ListNode
{
DATA data;
struct ListNode* next;
}但这里的DATA 是一种抽象的数据类型,即并未指定某种特定的类型。而编译器在编译这个结构体的时候,是需要具体数据类型,确定该结构的大小的。所以我们才会在c++的链表std::list里,看到是作为一个模板类实现,实例化的时候需要用实际存储的类型作为模板参数,std::list<Foo>。而在C语言中,并没有模板,那该如何设计一个通用的链表结构呢。
我们看看内核是如何解决这个问题的。内核中,链表的结构是这样的:
struct list_head {
struct list_head *next, *prev;
}然后就可以根据该结构,来定义对链表的一些操作,诸如insert/delete等。且慢,这里分明只有头尾指针,并没有实际数据的存储啊?
是的,但是仔细想想,insert/delete这些操作,其实是并不需要数据的,他们操作的是链表的表结构,并不涉及到数据,所以可以用一套统一的方式,作为库,或者说是基础设施,预先完成。那么实际的使用是怎样的呢?
struct FooNode {
struct list_head header;
Foo foo;
}如此,我们可以得到如下的内存分布。每个节点由链表的头来链接。而这些与foo数据无关的方法,是我们早就写好的、通用的方法。foo数据放在每个节点的后部,我们只要依上法,定义好业务节点,就能立马得到一套链表的方法,岂不美哉。
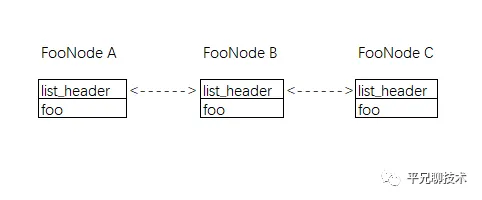
这也同时印证了软件设计中,**一个很重要的原则:分离变化与不变的部分。**可以将那些不变的部分,写的足够通用,尽可能的高效、稳定,将变化的业务部分就像填填空题一样,依葫芦画瓢地填进去就好了。这样当新的业务来临,你的通用部分(即核心模块)没有浪费,填入新的业务就立马可用了。这又是另外一个话题了。我们以后有机会再说(嗯,这坑是埋下了)。
嗯,这次我们先讲这两点。后续我们再聊其他的tricks。